
背景
在The transformer’s details一文中,Decoder最后一层$Softmax$输出预测token在词汇表是各个token的概率大小。
实际使用中,预测的token是连续生成的,那么怎么挑选预测的token会对结果有不同的影响
解码策略
greedy search
顾名思义,预测的每个token都是top-1概率大小的token。优势是简单效率高,不足之处在于步步最优不一定代表整体最优,很有可能陷入了局部最优。
举个例子:

如上图,按照贪婪搜索的方法,最终的预测序列是The cat is,但是从整体结果来看the red fox才是最佳答案。可以看出,贪婪搜索会忽略当前低概率token后续的高概率token。
sampling
random sampling
从模型输出的token概率分布中,随机选择一个预测token
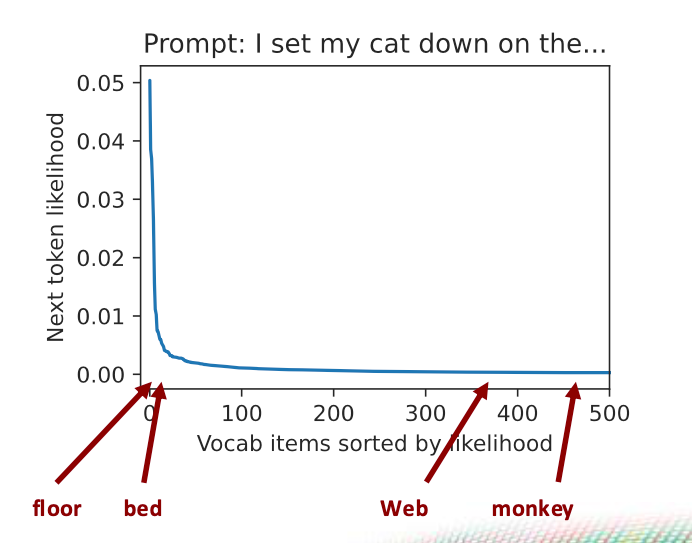
参考上图,使用随机采样的方法,I set my cat down on the后面很有可能跟web或monkey,因为词汇表中大部分的token概率数值都较低,整个词汇表概率分布呈现长尾现象。
random sampling with temperatue
\[P(Y_t=i)=\frac{exp(\frac{z_i}{T})}{\sum_jexp(\frac{z_j}{T})}\]引入$T$来计算输出token的概率分布,$T$大小与词汇表token概率分布的关系如下图
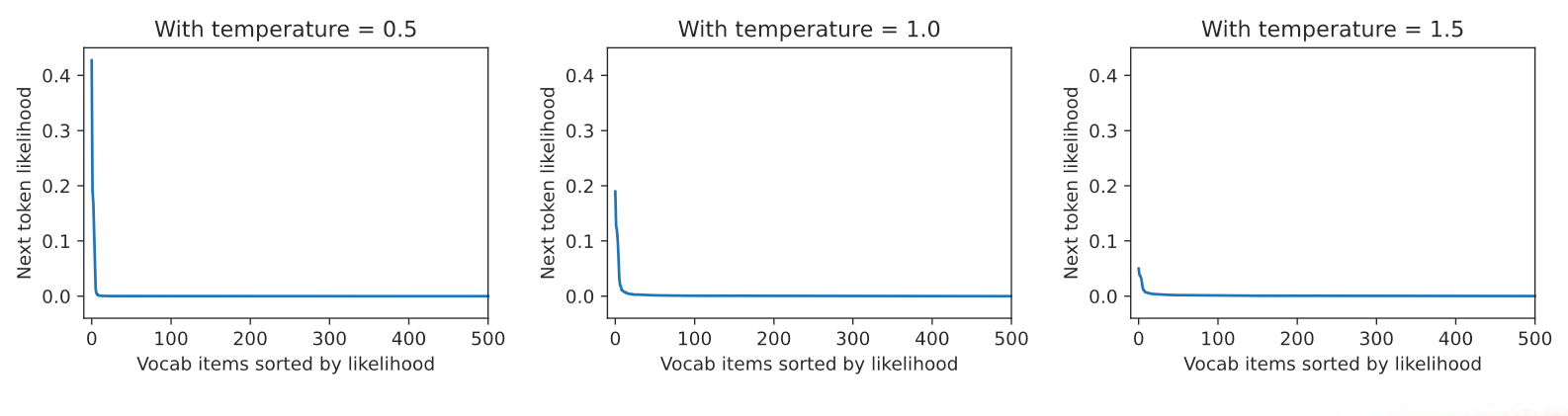
可以看出,温度越高,预测token整体概率分布越趋于均衡,左侧分布幅度越小。这也侧面说明,温度越高,文本预测结果越适合创作场景,因为不需要对结果有很高的准确度约束。
top-k sampling
只考虑概率最大的k个token,通常$k \in [10,50]$
这样仍存在选取不太可能的token作为输出的情况,比如概率分布左侧尖锐尾部很长的场景
nucleus sampling
相较于top-k采样,此方法不固定选择的token数目。它设定一个概率$p$阈值,选择的$k_t$个token概率和要不高于$p$
小结
使用温度,可以改变模型的输出概率分布,使其变得更加尖锐或者平滑;top-k或者top-p可以使得输出结果更加流畅
这三种方法相当于缩小与采样范围,从新的范围中选择一个token作为预测结果
beam search
目标是最大概率的预测序列
示意图如下,beam size为2
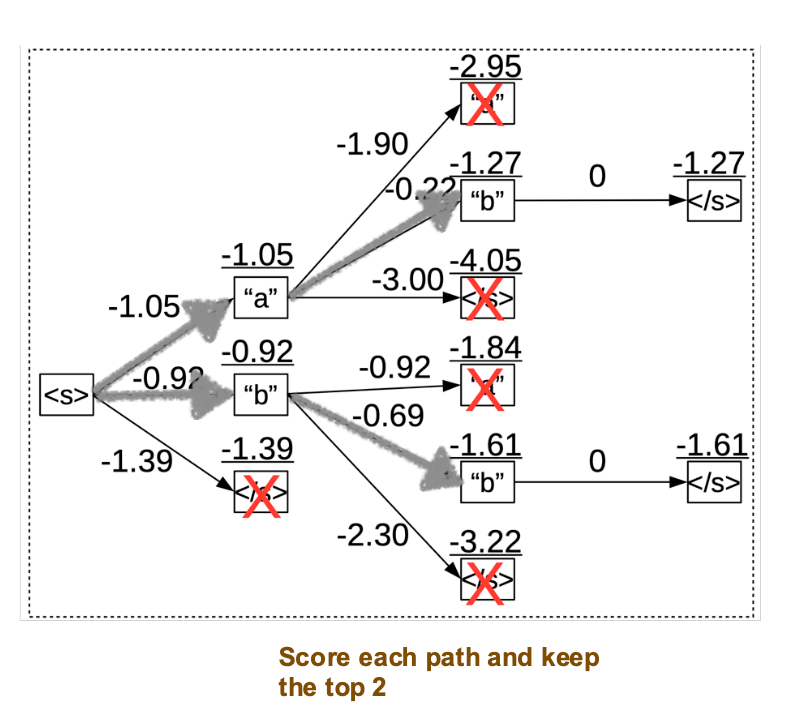
从上图可以看到,在每一轮预测,都会保留top-2结果;图中的灰色path(也称beams)就是被选择的结果。如果beam size变大,带来的计算量会显著增大。
beam search适合对最终整体结果正确性要求较高的场景,不适合创作性要求高的场景
小结
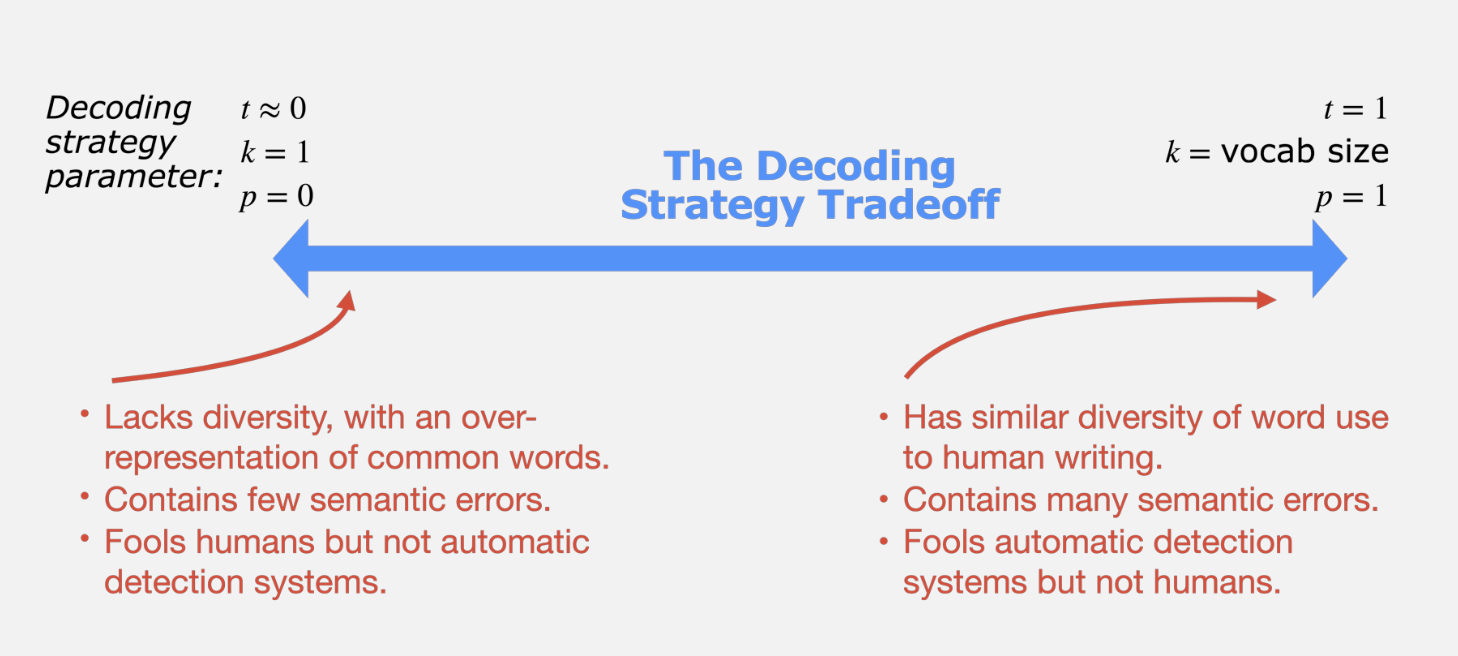
左右两端对应结果两极,通常根据场景设定对应的decoding策略参数
参考信息
- Decoding Strategies for Transformers
- Two minutes NLP — Most used Decoding Methods for Language Models
- cmu llm course