背景
自回归transformer模型
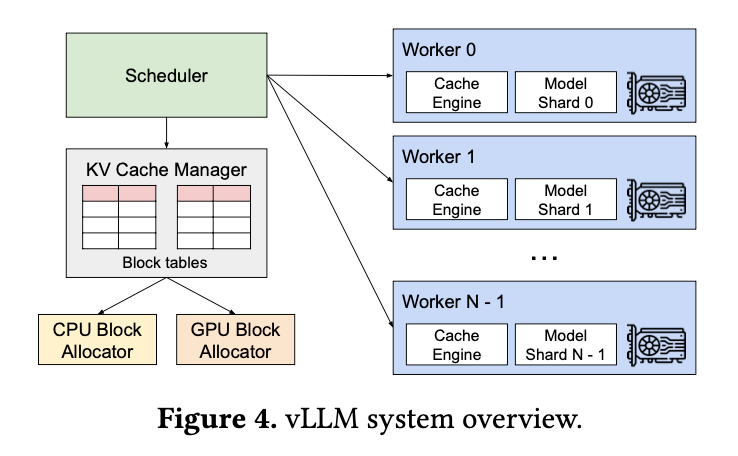
首先来看自回归transformer模型结构,如下图:
它主要包含以下部分:
- input
- embedding
- positional encoding
- Masked MultiHead Attention
- FeedForward
- Linear&Softmax
其中Masked-MultiHead Attention和FeedFoward作为一个基础模块可以不断堆叠。
数学表达式如下:
\[MaskMultiHead(Q,K,V)=Concat(head_1,head_2,\ldots,head_h)W^O \\\] \[head_i=Attention(QW^Q_i,KW^K_i,VW^V_i)\] \[W^Q_i \in \mathbb{R}^{d_{\text{model}} \times d_k}\] \[W^K_i \in \mathbb{R}^{d_{\text{model}} \times d_k}\] \[W^V_i \in \mathbb{R}^{d_{\text{model}} \times d_v}\] \[W^O \in \mathbb{R}^{h \cdot d_v \times d_{\text{model}}}\]从$W^O$的维度可以看出,$Concat$是在$head_i$行方向上进行
这里的Attention有些特别,公示如下:
\[Attention(Q,K,V)=Softmax(\frac{QK^T}{\sqrt{d_k}}+M)V\] \[M_{i,j}=0,j<=i\\ M_{i,j}=-\infty, i<j\]从网路结构图以及数学表达式可以看出,decoder会做大量的K,V,Q计算
Q由于每次计算只跟当前输入有关,无需缓存;但是K和V会涉及到历史token,所以需要缓存。
kv cache matters

针对KV进行缓存,一个直观的实现方法是在GPU内存上开辟连续空间用于存储,空间一部分用来存储历史token的KV矩阵,另一部分用来存储预测token的KV,当前prompt结果生成后再进行空间销毁。
这有些类似我们在程序内部不断进行new和delete操作,从而带来内存碎片。同样地,直接缓存会导致大量的内外部碎片(如上图所示),降低内存使用效率,折损LLM模型服务的性能。
Paged Attention机制解析
Linux上采用分页机制来缓解内存碎片同时复用内存空间,如下图所示

虚拟地址空间的page一一映射到物理空间的page

根据虚拟地址空间的地址,可以找到对应物理空间page内部的地址,如上如物理页内的offset
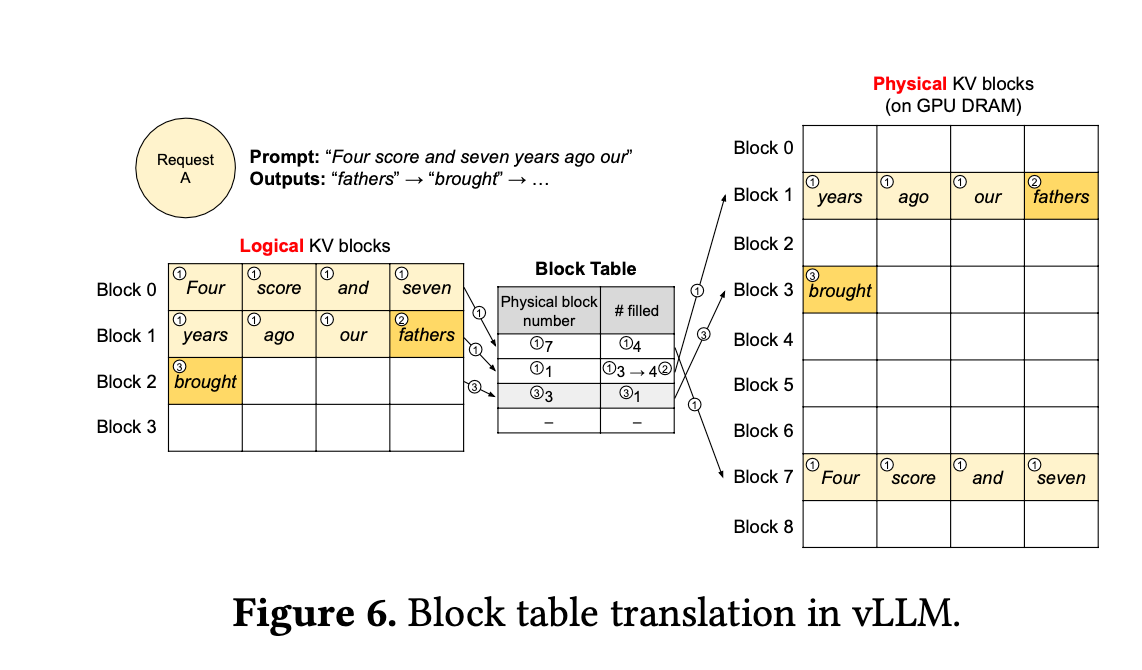
vLLM中Block概念跟Linux中的Page类似,Block Table进行逻辑block和物理block之间的映射
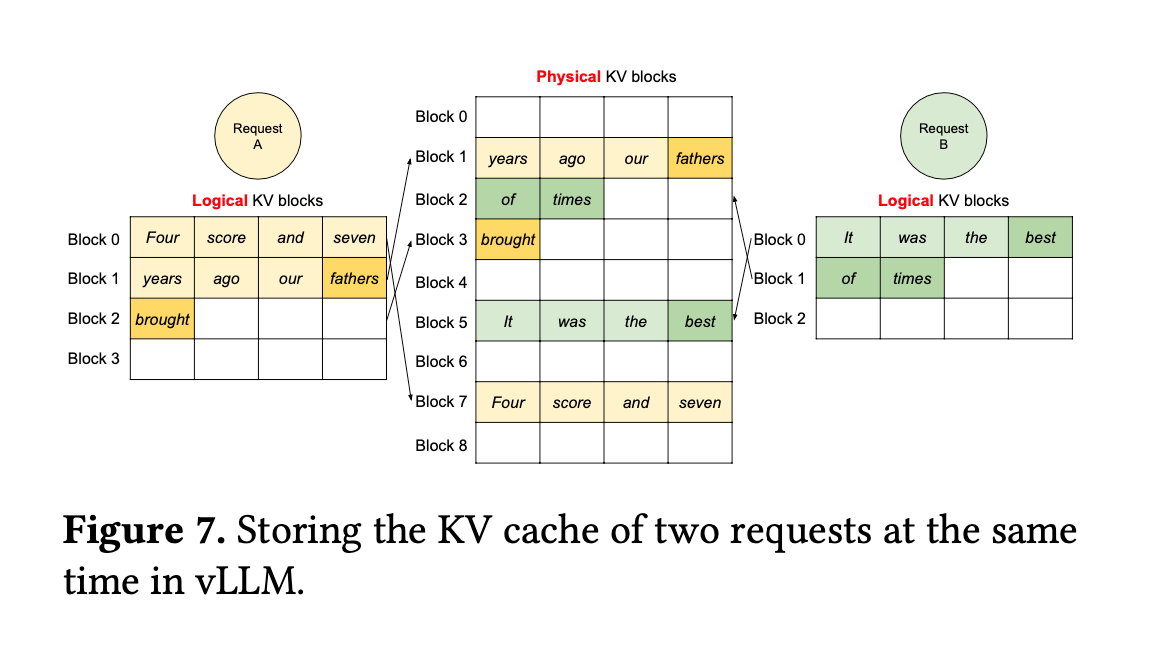
Request A和B类似Linux上的Process
在虚拟block层面,A和B既能拥有各自的KV存放空间相互隔离;在物理block层面,A和B进行内存复用
问题与讨论
- 逻辑KV block和Block table大小
对于单级分页,32位Linux,需要的页表大小为4M;64位Linux,需要的页面大小为512G,基本不可行
vLLm中单个block大小一般为256KB或512KB,逻辑KV block数量根据GPU内存来设置,也可以由系统自主决定;Block Table的大小跟逻辑block数量以及每个Block的映射信息大小决定
由于当前逻辑block数量不会很大,不像linux process的地址空间那么大,所以暂时没有必要进行多级映射