![]()
本文主要介绍DeepSeek V2的模型结构并用数学表达式分析模型计算过程。
Model Architecture
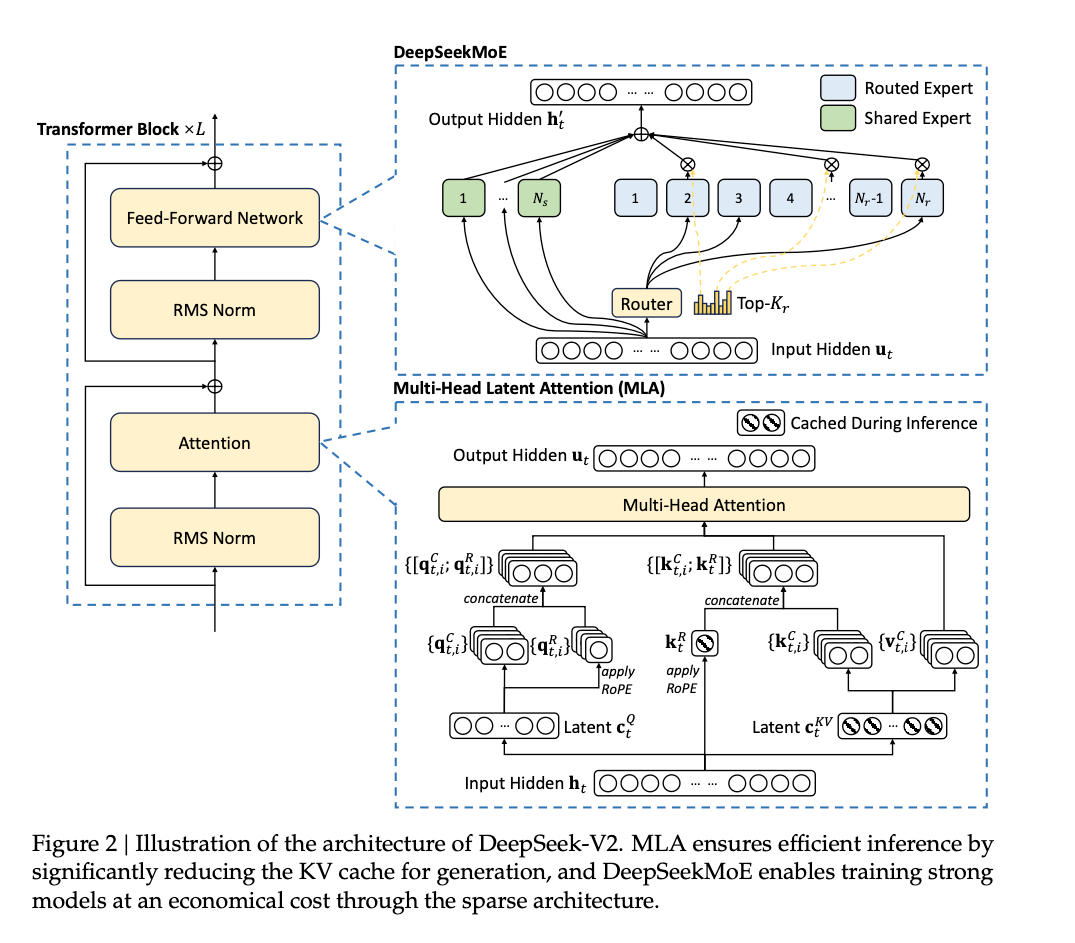
V2共计有60层,$h_t=5120$,注意力头数$n_h=128$,每个头的维度$R\in^{128}$
除了第一层的FFN,V2将每个transformer block中的FFN都替换为MoE层。
每个toekn,只会激活6个专家;V2共计参数量236B,对于每个token,激活的参数量为21B。
Transformer Block
MLA
KV联合压缩
输入$h_t \in R^{N \times 5120}$,这里的$N$
\[c_t^{KV}=h_tW^{DKV}\\ W^{DKV} \in R^{5120 \times 512}\] \[K_t^C=c_t^{KV}W^{UK} ,\quad V_t^C=c_t^{KV}W^{UV}\\ W^{UK} \in R^{512 \times (128\times128)},\quad W^{UV} \in R^{512 \times (128\times128)}\]输出的$K_t^C$和$V_t^C$矩阵大小为$N \times (128\times128)$
Q压缩
\[c_t^Q=h_tW^{DQ}\\ Q_t^C=c_t^QW^{UQ}\\ W^{DQ} \in R^{5120 \times 1536}\\ W^{UQ} \in R^{1536 \times (128\times128)}\]$c_t^Q \in R^{N\times1536}$
输出$Q_t^C \in R^{N \times (128\times128)}$
RoPE解耦
\[Q_t^{R}=RoPE(c_t^QW^{QR}),\quad K_t^{R}=RoPE(h_tW^{KR})\\ W^{QR} \in R^{1536 \times (64*128)},\quad W^{KR} \in R^{5120 \times 64}\]输出的$Q_t^{R}$大小为$N \times (64*128)$,$K_t^{R}$为$N\times64$
此时对于每一个头,$Q_t^{C_i} \in R^{N\times128}$,$K_t^{C_i} \in R^{N\times128}$,$Q_t^{R_i} \in R^{N\times64}$
\[Q_{final}^i=Concat(Q_t^{C_i},Q_t^{R_i})\\ K_{final}^i=Concat(K_t^{C_i},K_t^{R})\\\]Concat沿着行进行,输出维度
\[Q_{final}^i \in R^{N \times 192}\\ K_{final}^i \in R^{N \times 192}\\\]注意力计算
使用128个注意力头
对于每一个$head_i$,其计算如下:
\[head_i=softmax(\frac {Q_{final}^i{K_{final}^i}^T}{\sqrt{128+64}}){V_t^{C_i}}\\ V_t^{C_i} \in R^{N \times 128}\]$head_i$的输出大小为$N\times 128$
最后再经过一层映射,回到$R^{5120}$维空间
\[O_{concat}=Concat(head_1,head_2,...,head_{64})W^O\\ W^O \in R^{(128\times128) \times 5120}\]MoE Architecture
每个MoE层包含2个共享专家层和160个路由专家层,每个专家层的输出维度是$R\in^{1536}$
整体计算表达式如下:
\[\begin{equation*} \mathbf{h}'_t = \mathbf{u}_t + \sum_{i=1}^{N_s} \mathrm{FFN}_i^{(s)}(\mathbf{u}_t) + \sum_{i=1}^{N_r} g_{i,t} \mathrm{FFN}_i^{(r)}(\mathbf{u}_t) \end{equation*}\] \[\begin{align*} g_{i,t} &= \begin{cases} s_{i,t}, & s_{i,t} \in \mathrm{Topk}\left( \{s_{j,t} \mid 1 \leq j \leq N_r\}, K_r \right), \\ 0, & \text{otherwise}, \end{cases} \\ s_{i,t} &= \mathrm{Softmax}_i\left( \mathbf{u}_t^T \mathbf{e}_i \right) \end{align*}\]其中,$N^r=160$,$N^s=2$,$u_t \in R^{N\times5120}$
Expert
每个专家是一个独立的FFN,输入大小$N \times 5120$ ,输出大小为$N \times 5120$
公示如下:
\[Expert_i(x)=GeLU(xW_{down})W_{up}\\ W_{down} \in R^{5120 \times 1536}\\ W_{up} \in R^{1536 \times 5120}\]每个专家的输出大小是一样的,多个专家的输出会按照token对应专家的概率进行加权融合作为最终的专家网络输出
How to route
输入$N\times5120$,输出$N \times 160$
\[g_{raw}=u_tW_g\\ W_g \in R^{5120\times160}\\ s=Softmax(g_{raw})\]160个数值代表每个token选择对应专家的概率,按照概率大小取top-6对应的专家。
被选中的专家网络,其权重将被激活;相反,没被激活的专家,其权重将不会参与计算。