![]()
本文主要介绍DeepSeek R1的模型结构并介绍其模型生产流程。
Model Architecture
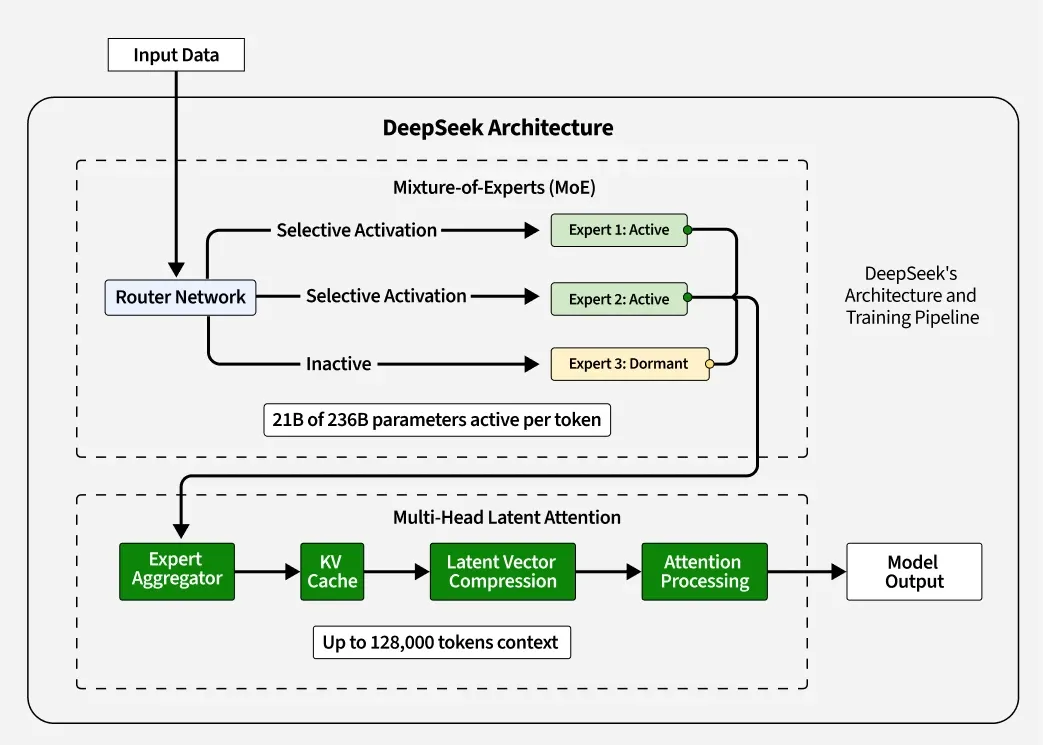
MoE Architecture
R1使用256个专家,但对于每个token只会激活其中8个专家,另有一个共享专家。
Router Network
输入token,数量$N$;输出$N\times256$的向量
第一步:输入$x \in R^{N\times7168}$投影至低维空间
\[h_{proj}=xW_{proj}\\ W_{proj} \in R^{7168 \times 2048}\]第二步:将注意力输出与投影后的输出进行concat
\[h_{fused}=Concat(h_{proj},h_{attn}) \in R^{N \times (2048+2048)}\]第三步:进行二次投影,输出大小$N \times 256$
\[Router=GeLU(h_{fused})W_{gate}\\ W_{gate} \in R^{4096 \times 256}\]256个数值代表每个token选择对应专家的概率,按照概率大小取top-8对应的专家。
被选中的专家网络,其权重将被激活;相反,没被激活的专家,其权重将不会参与计算。
Expert
每个专家是一个独立的FFN,输入大小$N \times 7168$ ,输出大小为$N \times 7168$
公示如下:
\[Expert_i(x)=GeLU(xW_{up})W_{down}\\ W_{up} \in R^{7168\times2048}\\ W_{down} \in R^{2048 \times 7168}\]每个专家的输出大小是一样的,多个专家的输出会按照token对应专家的概率进行加权融合作为最终的专家网络输出
MLA
KV联合压缩
输入$h_t \in R^{N \times 7168}$
\[c_t^{KV}=h_tW^{DKV}\\ W^{DKV} \in R^{7168 \times 128}\\ K_t=c_t^{KV}W^{UK} ,\quad V_t=c_t^{KV}W^{UV}\\ W^{UK} \in R^{128 \times 7168},\quad W^{UV} \times R^{128 \times 7168}\]输出的KV矩阵大小为$N \times 7168$
Q压缩
\[Q_t=(h_tW^{DQ})W^{UQ}\\ W^{DQ} \in R^{7168 \times 128}\\ W^{UQ} \in R^{128 \times 7168}\]输出$Q_t \in R^{N \times 7168}$
小结
可以看出,相比于MHA,MLA是将K\V\Q的计算过程转换为两步骤的低秩乘法过程,从而达到减少计算量的效果
RoPE解耦
\[Q_t^{R}=RoPE(h_tW^{QR}),\quad K_t^{R}=RoPE(h_tW^{KR})\\ W^{QR} \in R^{7168\times26},\quad W^{KR} \in R^{7168 \times 26}\]输出的$Q_t^{R}$和$K_t^{R}$大小均为$N\times26$
\[Q_{final}=Concat(Q_t,Q_t^{R})\\ K_{final}=Concat(K_t,K_t^{R})\]Concat沿着行进行,输出大小$N \times 7194$
注意力计算
使用64个注意力头 对于每一个$head_i$,其计算如下:
\[head_i=softmax(\frac {Q_{final}K_{final}^T}{\sqrt{112}})V_t\]其中
\[Q_{final} \in R^{N \times 138}\\ K_{final} \in R^{N \times 138}\\ V_t \in R^{N \times 112}\\\]这里的$138=112+26$,也就是说拆分头是对原来的$7168$维度进行拆分,将RoPE的26维追加到每个拆分的112维度中
$head_i$的输出大小为$N\times112$
最后再经过一层映射,回到$R^{7168}$维空间
\[O_{concat}=Concat(head_1,head_2,...,head_{64})W^O\\ W^O \in R^{7168 \times 7168}\]参考信息
- DeepSeek R1: Technical Overview of Its Architecture and Innovations
- Architecture Advancement on Transformers
- 深度学习中的注意力机制革命:MHA、MQA、GQA至DeepSeek MLA的演变
- DeepSeek核心架构-MLA:剖析低秩联合压缩优化KV缓存、提升推理效率的技术细节