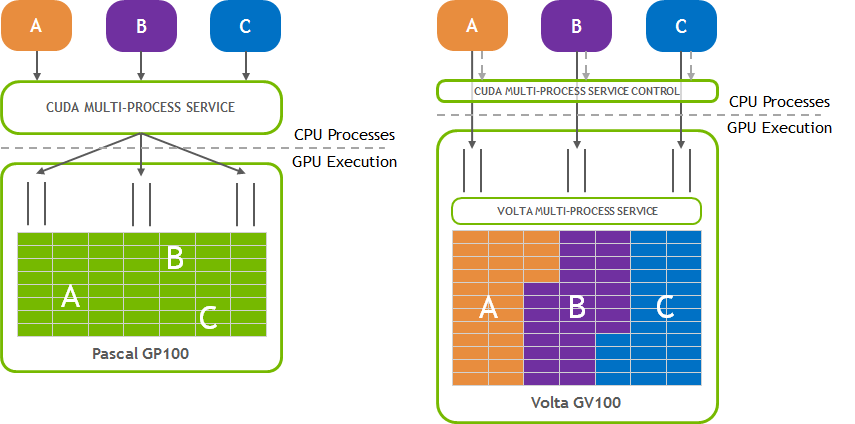
使用场景
-
减少多进程在GPU上的context switch开销 没有MPS,多进程任务在GPU上运行时,调度资源必须频繁的做切换;在MPS下,调度资源是可以共享的
-
提高GPU利用率 在MPS下,支持更高的并发
-
减少片上GPU的存储占用 在没有使用MPS时,单个进程运行在GPU上,GPU需要分配独立的存储和调度资源;使用MPS后,存储和调度资源可以为所有进程共享
调度资源是指GPU在管理和执行多任务时所需的底层硬件和软件资源,用于协调任务的提交、排队、分配和执行
使用场景例子
假设两个客户端进程A和B共享MPS Server:
传统模式
A和B各自占用独立上下文、命令队列和显存。
GPU需交替执行A和B的任务,频繁切换上下文,显存冗余。
MPS模式
A和B的任务合并到同一队列,共享显存池。
GPU按顺序执行A的matmul和B的conv2d内核,SM资源按比例分配(如A占70%,B占30%)。
显存利用率提升,任务延迟降低。
架构
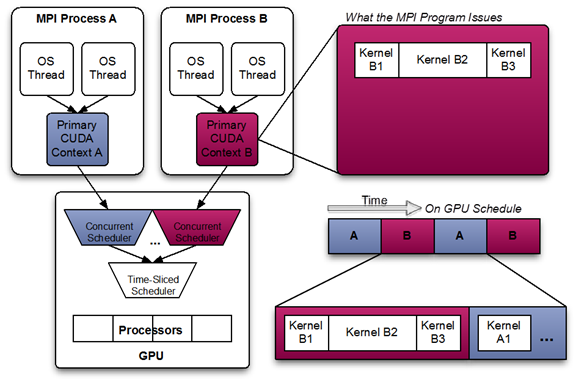
对于多个CPU process发起的cuda任务,scheduler会调配时间片分配给每个process;由上图可知,GPU在执行当前process任务一定时间后,会切换执行另一个process的任务,存在许多的context-switch。
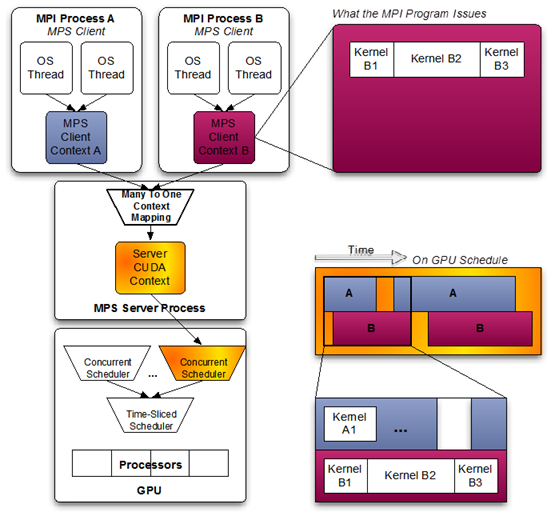
MPS server对多个process进行统一调度管理,从时间上看,各个process的任务可以比较好的overlap,达到同时执行的效果
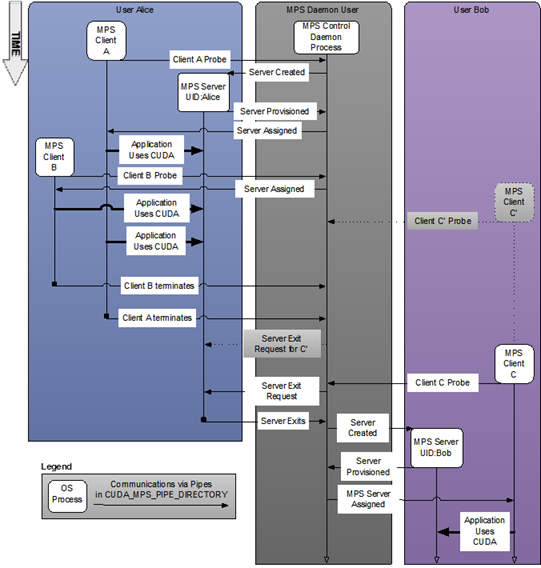
上图是多用户的MPS服务时许图,可以看到对于每一个用户,MPS control daemon都会创建一个server,但是每次只能有一个MPS Server处于活跃状态。
Alice的Client A和Client B共享创建的MPS Server;用户Bob的MPS server需等到Alice的server退出后才会创建
实践
本地NVIDIA T4单卡测试torcherve的pytorch模型吞吐情况,同时开启两个worker,实验结果如下

可以看到随着batch size的增大,MPS的优势才会体现,在实际应用中可能需要根据场景去调节相关MPS参数